.webp)
.webp)

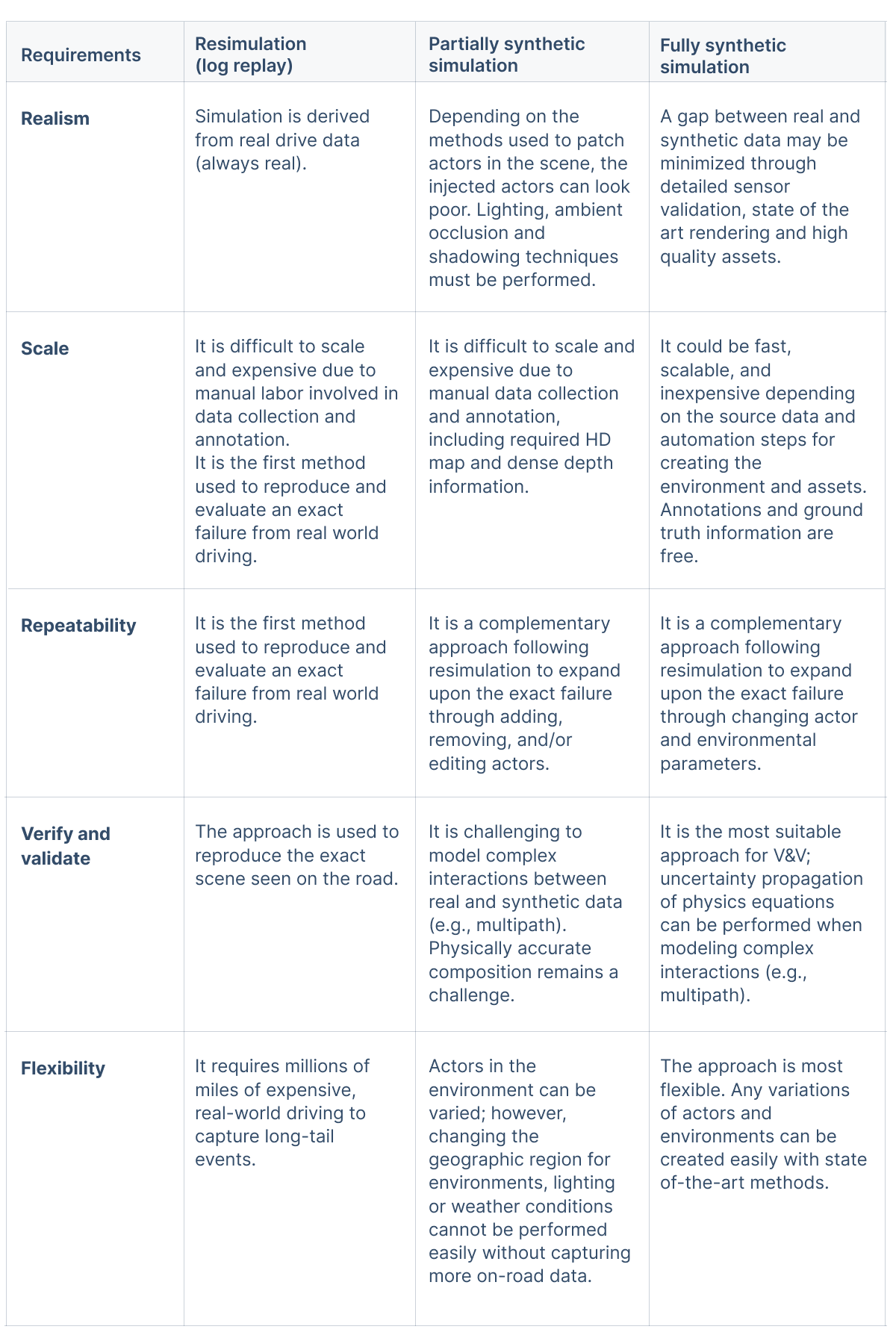
認識シミュレーションについてのブログシリーズのパート2では、前回の「研究から生産へ:認識シミュレーションの戦略(パート1/2)」で説明した認識シミュレーションへの一般アプローチに主要要件がどのようにマッピングされるかを説明します。認識シミュレーションは、ツールが次の要件を満たすことが重要です。
- リアリズム:シミュレーションツールは、現実での車両動作について正確に予測するため、実データとほぼ同等のデータを生成すること(図1)。
- スケーラビリティ:シミュレーションは、「トレーニングデータのフレーム数、または1日に実行できるテストの数とコスト」などの指標に合わせて最適化できること。
- 再現性:イベントが発生した場合、シミュレーションで確実かつ迅速に再現できること
- 検証および確認(V&V)機能:合成シミュレーションは物理的に正しいこと。不確実性分析は、実データと合成データの入力から出力までの各ステップで実行できること
- フレキシビリティ:エンジニアが(稀にしか発生しない)ロングテールイベントをカバーするために、路上で実際に起きるかどうかは関係なく、可能なイベントを作成できる必要があります

表1はさまざまな認識シミュレーションアプローチが主要な要件にどのように対処するかをまとめたものです。以下の各要件について詳しく説明します。
要件1:リアリズム
忠実さは、部分的または完全に合成されたデータで最初に議論になることが多いです。認識コンテキストでは、データ生成リアリズムは、物理的コンポーネント(センサー、シグナル伝搬、およびマテリアルの相互作用)とシーン構成(ライティングとレンダリング、アクター、環境、およびディテール)に大まかに分類できます。方法に応じて、シミュレーションと実データのギャップを最小限にするデータセット生成のため、コンポーネントの一部またはすべてが必要になります。
- 部分合成シミュレーション:実際のセンサーデータでのアクターの移動、削除、または追加には、それぞれ独自の課題があります。アクターをセンサーデータに挿入する場合、現実に近づけるために必要な情報があります。まず、シーンに配置されるアクターのモデルが必要です。これは、3DのCG、CADモデル、またはスキャン写真測量と点群の組み合わせのモデルです。次に、HDマップデータとシーンのdense depth情報より、シーンがどういう状態であるか理解させる必要があります。最後に、環境ライティングを考慮して、実際のパッチを適用した合成アクターの構成が必要です。通常、アーティファクトは特にパッチを適用したアクターオクルージョンの場合、構成ステップで生成されます。ニューラルネットワークを使用して合成ステップを実行すると、結果が物理的に正確でなくなる可能性があります。これについては、検証のセクションで詳しく説明します。逆の場合、センサーデータからアクターを削除するときは、ある程度現実的な方法で削除された穴にパッチを適用する必要があります。そのオブジェクトが何を遮っていたのか、または何によって遮られていたのかに応じて、パッチを正しく適用するための多くのエッジケースがあります。アクターの追加・削除後のリアリズムは、現在も研究されているトピックです。
- 完全合成シミュレーション:現実とのギャップの最小化は、詳細な環境、材料、およびセンサーの検証を通じて実現します。重要なリアリズムは、詳細で多様なシーンを丁寧に追加することで得られます。限界まで忠実にしたいという要望はよくありますが、リアリズムはユースケースと一致する必要があります。ネットワークのトレーニングでは、ベースとなるシーンに大きな多様性と微妙な逸脱が必要になる場合がありますが、システム検証のユースケースでは、障害を再現するための詳細な物理モデリングに重点を置く場合があります。Dense LIDARスキャンや写真測量などの他の手法を使用して、環境全体で使用される3Dコンテンツを作成できます。通常、忠実度とスケールにより、リアリズムがどこまで求められるか決まります。
要件2:スケーリング
認識シミュレーションを実行するために必要なインフラストラクチャは、重要な考慮項目です。実際のセンサーと合成センサーは非常に大量のデータを生成するため、トリアージして効果的に整理します。データのトレーニングとテストの準備後、シミュレーション実行前に必要な計算についてさらに考慮が必要です。モーションプランニングシミュレーションとAVコードは通常CPUベースなのに対し、認識AVソフトウェアと合成センサーシミュレーションはどちらも、ニューラルネットワークまたはレンダリングのいずれかがGPUにて実行する必要があります。クラウドシミュレーションは、回帰テストを毎晩実行するように設定できて、新しい基本シナリオとパラメーターのバリエーションを体系的に追加できます。これら各ステップは、シミュレーションのフレームあたりのコストにつながります。誤った認識シミュレーションデータを使用した最適化が不十分なセットアップは、開発に数百万ドルを無駄にする可能性があります。
- 再シミュレーション(ドライブログの再生):認識に関するメトリックを生成するには、実データのタグ付けが必要です。大規模な実データセットが複雑な例として、2019年8月にリリースされたWaymoのタグ付けオープンデータセットは、6.4時間のドライブデータで、2,200万の3D / 2Dボックスが含まれていました。データタグ付けのコストは、(より高価な)フルマネージドサービスから(より安価な)ラベリングソフトウェアの使用までさまざまですが、AVプログラムは、境界ボックスとタグ付けを追加するだけで数百万ドルかかることがあります。セマンティックセグメンテーションは、実データの場合、フレームあたりのコストも大幅に高くなります。
- 部分合成シミュレーション:アクターのパッチ適用に必要なシーン理解に必要なレベルに到達には、通常、HDマップ情報とdene depth情報が必要です。場合によっては、セマンティックセグメンテーションも必要です。これは、最もスケーラブルではないアノテーションです。パッチが適用されたアクターには費用の負担なしでラベルが付けられます。これは、再シミュレーションよりも優れています。構成されたフレームを生成するために、実データよりも計算要件が増加しますが、一般に、この方法は、再シミュレーションのみを使用するよりも拡張性が高くなります。
- 完全合成シミュレーション:タグ付けのスケーリングを目的とした合成データは、シーンのすべてのグランドトゥルースを認識することで、自動タグ付けが可能です。速度とコストで大きなメリットがあります。自動アノテーションは非常に複雑な数学およびアルゴリズムの挑戦になりますが、コード化できればすべてのデータセットに適用できます。完全に合成されたデータは、セマンティッククラス、一貫したID、深さ、速度など、実際のまたは部分的に合成されたアプローチでは保証されないグランドトゥルース情報も提供します。完全な合成データのスケーリングは、環境と合成データの作成にて問題が発生することがあります。最高の忠実度とリアリズムは、写真測量などのマニュアル技術にて環境を作成し、パストレーシングなどのレンダリング方法を実装で得られます。我々は、これらの方法は時間と計算コストの両方の観点からスケーラブルではないと考えています。完全合成データの最もスケーラブルな形式は、手続き型生成により実際の場所と一致しない合成環境を生成するか、HDマップデータから手続き型生成を利用することになります。手続き型生成とリアルタイムレイトレーシングを組み合わせることで、スケールとリアリズムの両方の要件を満たすことができます。
要件3:再現性
実用グレードのシステム開発では、発生しうる実際の障害モードについて深く洞察する必要があります。これは、誤って表示された画像が検出障害につながるなどの一般的に発生するシナリオから、さらに下流のシステムパフォーマンスやシーン構成での障害やコーナーケースにまで及ぶ可能性があります。いずれの場合も再現性は問題が発生した原因を理解する上で重要で、将来そのような障害の発生を減らすことに役立ちます。認識の再現性はいくつか方法がありますが、まとめると、発生している正確なシーン、センサー、物理プロセスを再現し、シミュレーションでそのシナリオと条件をいくらでも繰り返し生成するということになります。
そのようなシナリオの例として、フロントレーダーが誤検出して信号を発する、センサーフュージョンレイヤーの障害があります。実際には、レーダーは意図したとおりに動作している可能性がありますが、特定のシーンジオメトリとマルチパスのために、複数のゴーストターゲットが生成されてしまいます。この失敗の原因を確認するために、次のようなアプローチをとることができます。
- 再シミュレーション:ドライブログを使用して正確に障害再生することが、この場合は最初の方法になります。ログからシナリオが作成されると、センサーフュージョンスタックの将来のバージョンでこの障害ケースを処理できるか、センサー構成に直接対処する必要があるほど重大な障害であるかを確認できます。
- 完全合成シミュレーション:物理学ベースで再現したシナリオとオリジナルログとの相関関係を示し、このイベントを拡張し、このような障害に対する堅牢性を向上させ、同様の状況で今後は対応できるとみなすこともできます。ベースログシナリオと、このシナリオのすべての潜在的な合成バリエーション(パラメータースイープ)は、将来、システムの回帰テストとして使用することもできます。
要件4:検証と妥当性確認
ドライブログシミュレーションが正確な路上状態再現に検証されるとすると、検証と妥当性確認のトピックは、主に部分合成および完全合成になります。トレースできる開発のコアとなるのは、検証済みのシステムと環境です。検証のプロセスを通じてのみ、アプローチが特定のユースケースの物理現象を適切に表せていると確証できます。このプロセスは、より複雑なシナリオに移行する前に、分離した基本動作が適切かを保証することから始まります。したがって、実データと合成データで認識アルゴリズムのパフォーマンスをテストすることは非常に重要ですが、メインのタスクは部分的または完全に合成されたセンサーデータが(不確実なものを測定している中で)正しいシグナルを生成していることを検証することです。完全合成アプローチはこれを主な目的とし、多種類のセンサーで実際の測定と合成測定を実行して、基礎となる法則と方法を検証および確認することにより、ドメインギャップを徐々に埋めます。私たちの知る範囲では、リアルタイムの自動運転車センサーシミュレーションでは、これが厳密に行われた例は公開されていません。
このような例の1つは、上記のマルチパスの例で、3面コーナーリフレクターの適切なレーダー断面積(RCS)シミュレーションの保証です。オブジェクト形状は比較的単純ですが、戻り信号の大部分は、複数の反射の比較的複雑なシミュレーションに依存します。このオブジェクトの入口開口部を一部でも塞ぐと、最終結果に大きな影響を与える可能性があります。このアナロジーは、すべてのセンサーについてより広くセンサーモデリングに当てはめることができます。正確な結果を得るには、シーン全体を理解する必要があります。
- 完全合成シミュレーション:図2は、完全合成レーダーセンサーに対して実行されたRCS実験の例を示しています。ここでは、理論的結果の生成のため、環境とセンサーの計算を段階的にトレースできます。

- 部分合成シミュレーション:合成データと実データの融合により、シーン内の対象オブジェクトの代用(合成)モデルを使用してマルチパスを追加でモデル化できます。合成シミュレーションを通常どおり実行し、生成された合成データの、新しく挿入された(完全に合成された)アクターと相互作用しない部分を削除することで、実データの整合性を維持しながら、これら2つのデータソースを融合できます。別の言い方をすれば、合成オブジェクトのマルチパス効果が追加され、リターンに影響を与えます。
要件5:フレキシビリティ
シミュレーションのフレキシビリティは、実用システムの開発速度と市場投入までの時間に大きく影響します。大規模フリートの実データを使用するとある程度のフレキシビリティが得られる場合がありますが、シミュレーション実行中の開発者による、環境やセンサーのリアルタイム変更は、完全合成シミュレーションでのみ可能です。
- 再シミュレーション:オンロードデータは、一般的にフレキシビリティとロングテールケース発見が課題になっています。フレキシビリティは主に、多数の車両を保有し、車載システムを使用して車両から特定のデータを照会する機能によって得られます。
- 部分合成シミュレーション:合成データで拡張された実データは、環境内のアクターを変化させて任意の場所に配置できるため、よりフレキシビリティがあります。ただし、地理的に正しく配置された環境、ライティング、または天候条件の変更は簡単には実行できません。
- 完全合成シミュレーション:フレキシビリティに制限はありません。世界中どこでも予想または遭遇するロングテールイベントは、すばやく再現できます。基本シナリオが作成されると、他の何千もの潜在的なバリエーションもシミュレートできます。 Applied Intuitionは通常、バリエーションを検討するためにStructured Domain Randomization(SDR)を使用しますが、Full Domain Randomizationでも可能です。このタイプのアプローチは、合成シミュレーションを使用した場合にのみ可能です。
Applied Intuition のアプローチ
認識シミュレーションアプローチは、トレーニング、テスト、および検証のニーズを満たすのに十分にスタンドアロンではあり得ないことを認識しており、経験から実用システムの厳しい要件を満たすには多変量アプローチが必要だと考えます。私たちはあらゆる形態の認識シミュレーションをサポートするツールを構築しており、研究から生まれた新しい実行可能なアプローチを模索し続けます。詳細については、エンジニアリングチームにお問い合わせください。
