.webp)
.webp)

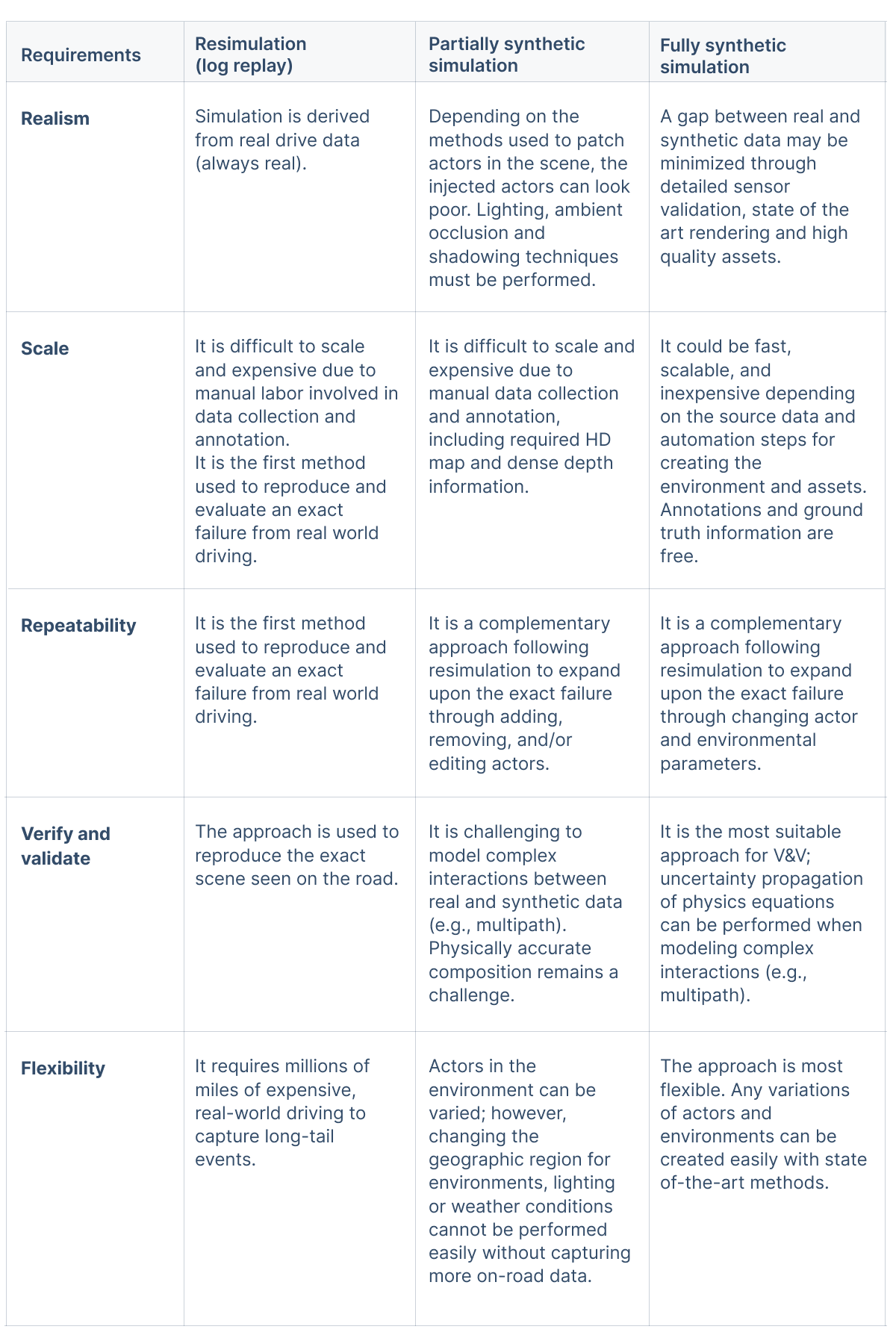
In the second part of the perception simulation blog series, we’ll explore how key requirements map to the common approaches to perception simulation discussed in the first post, “From Research to Production: Strategies for Perception Simulation (Part 1 of 2)”. For perception simulation, it is critical that simulation tools meet the following requirements:
- Realism: The simulation tool should generate data that is indistinguishable from real data in order to make accurate predictions about the behavior of the vehicle in the real world (Figure 1).
- Scalability: Simulation should be optimized for metrics such as “how many frames of training data or how many tests can be run per day and at what cost.”
- Repeatability: When an event occurs, it should be reproduced reliably and quickly in simulation.
- Ability to verify and validate (V&V): Any synthetic simulation should be based on physics equations. Uncertainty analysis could be performed through each step of input to output for real versus synthetic data.
- Flexibility: Engineers should be able to create any possible event, whether seen on the road or not, to cover the long tail events.

Table 1 shows the summary of how different perception simulation approaches perform against five key requirements. We’ll go deeper into each requirement below.
Requirement 1: Realism
Fidelity is often one of the first topics in the discussion around partially or fully synthetic data. In the context of perception, data generation realism is roughly broken down into components of the physics (sensors, signal propagation, and material interaction) and the scene composition (lighting and rendering, actors, environment, and details). Depending on the method of simulation, some or all of these components are required in order to produce datasets that minimize the gap between simulation and real-world data.
- Partially synthetic simulation: Moving, removing or adding actors to real sensor data comes with challenges. To inject an actor into sensor data, several pieces of information are needed to do so realistically. First, a model of the actor to be placed in the scene is needed. This can be a 3D computer graphics model, a CAD model, or a model based on combinations of scanned photogrammetry or point clouds. Then, scene understanding is needed using the HD map data and dense depth information from the scene. Finally, a composition of the real and patched synthetic actor is required with the environment lighting properly taken into account. Artifacts are typically produced in the composition step, especially in cases of patched actor occlusion. If the composition step is performed using a neural network, the results can become non-physically accurate. For the opposite case (an actor is removed from the sensor data), the hole needs to be patched in a somewhat realistic way. Depending on what that object is occluding or being occluded by, there are many edge cases to getting the patching correct. The realism in adding and removing actors is an ongoing research topic.
- Fully synthetic simulation: Minimizing this gap is accomplished through detailed environment, material, and sensor validation. Significant realism also comes from carefully populating scenes with detailed diversity. While it is often tempting to reach for the highest-fidelity hammer, the realism must match the use case. Training a network might require great diversity and subtle deviations in the underlying scene, while a system validation use case might focus more on the detailed physics modeling to reproduce failures. Other techniques such as dense lidar scans or photogrammetry can be used to create the 3D content used throughout the environment. There is typically a trade-off where fidelity versus scale will determine how far the realism is pushed.
Requirement 2: Scale
The infrastructure required to run perception simulations is a key consideration. Real and synthetic sensors produce extremely large amounts of data that must be triaged and organized effectively. Once the data is ready for training and testing, another consideration is compute needed to run simulations. Whereas motion planning simulation and AV code are typically CPU-based, both perception AV software and synthetic sensor simulation require GPUs to run for neural networks or rendering. Cloud simulations need to be set up in a way that regression tests can be performed on a nightly basis and new base scenarios and parameter variations can be added systematically. Each of these steps leads to a cost-per-frame of simulation. A poorly optimized setup using the wrong breakdown of perception simulation data can lead to millions of dollars wasted in development.
- Resimulation (log replay): In order to produce metrics on perceptions, real data must be annotated. As an example of the complexity of large scale real datasets, Waymo’s annotated open datasets released in August 2019 were based on 6.4 hours of drive data and contained 22 million 3D/2D boxes. The cost of data annotation varies from fully managed services (more expensive) to the use of labeling software (less expensive), but an AV program could spend many million of dollars just on adding bounding boxes and annotations. Semantic segmentation is also significantly more expensive per frame for real data.
- Partially synthetic simulation: In order to reach the level of scene understanding that is needed to patch an actor, typically HD map information and dense depth information are needed. In some cases semantic segmentation is also needed, which is the least scalable form of annotation. Patched actors are labeled for free, which is an advantage over resimulation. Although there are increased compute requirements in order to generate the composed frames, this method generally scales better than using only resimulation.
- Fully synthetic simulation: Focusing on scaling annotations, synthetic data is aware of all ground truth about a scene and therefore can contain automated annotations. This is a key benefit in speed and cost. While automated annotations are an extremely complex mathematical and algorithm challenge, once they are coded, they can be applied to every dataset. Fully synthetic data also offers ground truth information such as semantic classes, consistent IDs, depth, and velocity that are not guaranteed in the real or partially synthetic approaches. The scaling of fully synthetic data can suffer when it comes to creating environments and assets. The highest fidelity and realism come from creating environments using manual techniques like photogrammetry and implementing rendering methods like path-tracing. Based on our knowledge, these methods are not scalable due to both time and compute costs. The most scalable forms of fully synthetic data come from using procedural creation either to create synthetic environments that do not match real world locations, or using procedural creation from HD map data. Combining procedural creation with real time ray-tracing, requirements for both scale and realism can be met.
Requirement 3: Repeatability
In the development of production-grade systems, it is often necessary to obtain deep insight into possible and actualized failure modes. This could range from commonly occurring scenarios (e.g., an incorrectly exposed image leading to a detection fault and further downstream failures) or corner cases in either system performance or scene composition. In either case, repeatability is an important part of understanding why something went wrong and helps to reduce the likelihood of such failures in the future. While perception repeatability could take many forms, it boils down to reproducing the exact scene, sensors, and physical processes that are taking place and being able to repeatedly produce that scenario and conditions exactly forever in simulation.
In one such scenario, we may have a sensor fusion layer failure in which the front radar misreports detections. In reality, the radar may be operating as intended but multiple ghost targets are generated due to specific scene geometry and multipath. In order to confirm the cause of this failure, different approaches could be taken.
- Resimulation: Replaying the exact failure using the drive log would be the first method used in this case to reproduce the failure. Once the scenario is created from the log, we would be able to verify that any future version of the sensor fusion stack is able to handle this failure case or the failure would be severe enough that the sensor configuration would need to be addressed directly.
- Fully synthetic simulation: We could also turn to physics-based reproduction of the scenario to show correlation with the initial logs, expand upon this event to improve robustness to such failures, and assert future compliance in similar situations. The base log scenario and potential synthetic variations of this scenario could be used in the future as a regression test for the system.
Requirement 4: Verification and Validation
Assuming drive log simulation is verified to reproduce the exact conditions seen on the road, the topic of verification and validation mostly applies to the partially synthetic and fully synthetic methods. At the core of traceable development is the need for validated systems and environments. Only through the process of validation, confidence can be developed that an approach will adequately represent the physical phenomena of interest for a given use case. This process begins by validating up from the fundamentals which ensures proper behavior in isolation before moving to more complex scenarios. Therefore, while testing the performance of perception algorithms on real and synthetic data is extremely important, it is secondary to the primary task of verifying and validating that partially or fully synthetic sensor data is producing (within a measure of uncertainty) the signals that are expected to be produced. Fully synthetic approaches gradually close the domain gap by considering this as the primary objective and performing real versus synthetic measurements with a large number and type of sensors to verify and validate the underlying equations and methods. To our knowledge, for real time autonomous vehicle sensor simulations, this type of rigorous activity has not been performed publicly.
One such example of this refers back to the above example of multipath and ensuring proper Radar Cross Section (RCS) simulation for a trihedral corner reflector. While the reflector object has relatively simple form, it relies upon a comparatively complex simulation of multiple bounces for the majority of return signal. Occluding even just part of this object's entrance aperture could have a significant impact on the final result. This analogy could be made to sensor modeling more broadly for all sensors. In order to produce accurate results, full scene understanding is required.
- Fully synthetic simulation: Figure 2 shows an example of an RCS experiment performed for a fully synthetic radar sensor where both the environment and sensor calculations can be traced step by step in order to produce the theoretical result.

- Partially synthetic simulation: Fusion of synthetic and real data can additionally model multipath using stand-in (synthetic) models for objects of interest in the scene. We can fuse these two sources of data while maintaining the integrity of the real data by running synthetic simulation normally and removing parts of the generated synthetic data that do not interact with the newly injected (fully synthetic) actor. Said another way, multipath effects for synthetic objects are added to influence the returns.
Requirement 5: Flexibility
The flexibility at which simulations can be run has a huge impact on the development speed and time to market for production systems. While some flexibility may be achieved using real data with large fleets, giving developers the ability to change environments or sensors in real-time during a simulation run is only capable with fully synthetic simulations.
- Resimulation: On-road data generally struggles in the area of flexibility and finding long tail cases. Flexibility is mostly obtained through having large fleets of vehicles and the ability to query specific data from vehicles using onboard systems.
- Partially synthetic simulation: Real data augmented with synthetic data has a bit more flexibility because the actors in the environment can be varied and placed in any potential location. However, changing geo-located environments, lighting or weather conditions cannot be performed easily.
- Fully synthetic simulation: There is no limit to the flexibility. Any long tail event that is expected or encountered anywhere in the world can be recreated quickly. Once the base scenario is created, thousands of other potential variations can also be simulated. The Applied Intuition team has typically used some form of Structured Domain Randomization (SDR) for considering variations, but there is also promising work in fully Randomized Domains. This type of approach is only possible using synthetic simulation.
Applied Intuition’s Approach
We recognize that no perception simulation approach can be sufficiently standalone to meet the training, testing, and validation needs and it takes a multivariate approach to meet the stringent requirements of a production system. We’ve built tools to support all forms of perception simulations and will continue to develop new viable approaches that we see come out of research; reach out to our engineering team to discuss more in detail.
