.webp)
.webp)

過去10年間で、自動運転車(AV)の認識システムは、実験や研究の対象からから実用されるフェーズに移行しました。シミュレーションは様々な形でこの最先端技術のベースになるため、実用に対応できるレベルである必要があります。実用に使われるシステムでは、トレーニングまたはテストが必要な広範囲のイベントをカバーするために、複数のタイプのシミュレーションが必要です。このブログポストのパート1では、認識シミュレーションの異なるアプローチと、それらを組み合わせる手法を紹介します。パート2では、それらのシミュレーションの主要要件について説明します。
確立されている認識シミュレーションのアプローチ
認識シミュレーションにはいくつかの方法があり、各アプローチにはそれぞれトレードオフがあります。 Applied Intuitionでは、実際の走行データを利用できる範囲で使用し、検証済みの合成シミュレーションツールをロングテールイベントに応用する、堅牢なハイブリッドソリューションを開発しました。このソリューションでは、認識シミュレーションを3つに分類しますが、さらにそれぞれのハイブリッドがあります。
ドライブログの再シミュレーション
当社が再シミュレーションと呼ぶドライブログの再生は、実データを検証したり、予期しない障害、または「Unknown Unkowns (知らない知らないこと) 」をテストするのに非常に役立ちます。たとえば、車両が高速道路に落ちているマットレスなど、予期しない物体に遭遇して回避するために隣の車線に安全に移るケースです。この状況では、再シミュレーションによって車両の動作を改善できます(つまり、車両の認識システムでより遠くから測定できるようにして、別の車線への移行をよりスムーズにします)。再シミュレーションにより、現実世界の一般的イベントとロングテールイベントの両方をキャプチャできます。このアプローチの設定は比較的迅速に行えますが、実際の課題は、収集できるデータの量を増やすためのオペレーションとコストにあります。有用性は、所有するデータセットの多様性に依存し、車両が走行した場所と経験に限定されます。場所、環境条件、オブジェクトタイプなどのバリエーションは変更できません。また、認識システムのスタックまたはセンサーが更新されて、ドライブデータが古くなり、実用システムで使用できなくなる場合もあります。
部分合成シミュレーション
合成データで拡張された実際のドライブログの使用は、現実の世界で遭遇するシナリオに追加でテストできる別の方法です。このアプローチは、オブジェクトを実データから移動、追加、または削除する、ログストリーミングの合成データによる拡張です。実際のシーンからのセンサーデータのほとんどは保持され、さまざまな潜在的なシーンのバリエーションが可能です。この方法は、Applied Intuitionの再シミュレーションツールでは「アクターパッチング」と呼ばれ、ドライブデータにアクターを追加または削除できます。前のセクションのマットレスの例において、マットレスの位置を変更し、スタックが自律走行モードの解放シナリオのバリエーションをどのように処理するかをテストできるようになりました(図1)。モーションプランニングでのオブジェクトレベルの再配置はすでに業界では一般的ですが、センサーデータ内のオブジェクトの置換は比較的新しい方法です。データの信頼性が失われないレベルでのオブジェクトの変更には制限があります。

ドライブログへのアクターの挿入または削除は簡単ではありません。カメラ、レーダー、LIDARなどの一般的な自動運転で使用されるセンサーには、それぞれ課題があります。カメラの場合、物理的に正しい特性を持つアクターを挿入することは、現在進行中の研究分野です。 LIDARやレーダーの場合、実際に環境がないため、マルチパスなどの複雑な相互作用を正確かつ簡単にシミュレートできません。したがって、オブジェクトの表面の反射が正しくなく、実データと合成データの境界は、自然な状態を保つために複雑になることがよくあります。複雑なオクルージョンは非常に難しく、シーンに関する実データの詳細情報が必要になります。これ課題を解決するために、弊社では最先端のディープラーニングおよび敵対的生成ネットワーク(GAN)を検討していますが、現在は、これらの手法はまだ実用環境に対応できていません。これらの方法が実用環境に対応できればパフォーマンスとスケーラビリティが我々の顧客にメリットがあるため、弊社では引き続きこの方針でシステムを強化していきます。
完全合成シミュレーション
再シミュレーションとは対照的に、完全合成シミュレーションでは無数のイベントを作成できます。同じ落ちているマットレスの例でも、夜間の降雨状態にしたり、路上に無数のオブジェクトを配置して、シナリオをシミュレートできます。ほとんど遭遇しない現象でも無限に増やしてテスト可能です。これは理想的な解決策のように見えますが、合成環境と、実際の環境やセンサーにはドメインギャップがあります。この点については、このブログシリーズのパート2で詳しく説明します。
物理的に正確な合成データは、認識アルゴリズムのトレーニングとテストの両方で使用できます。基本シナリオの大規模なセットを生成する従来のアプローチ、またはドライブログデータから再生した合成シーンを基に、データを作成開始します。環境は様々な種類の地図データからすばやく作成されます。また合成データは、バリエーションを最大にするために手続き型生成にて作られます。そこから、Structured Domain RandomizationやFull Domain Randomizationなどの手法で、現実世界を超える分散を追加することで、アルゴリズムの堅牢性を高めることができます(たとえば、車体の色の豊富さ)。
開発では特定のレアイベントの処理に焦点を合わせる場合があります。これらは、特定の障害モードを対象としていることが多く、完全合成シミュレーションにより、実データが使えないテストプランを埋めることができます。例としては、近距離のオートバイ、路上で転倒した車、めったに遭遇しない車両などがあります(図2)。危険すぎて収集できないデータや、レアなデータは簡単に生成可能です。

適用する内容によっては、完全合成シミュレーションには多大な労力が必要になる場合があります。このようなことは、オンラインリソースとレンダリングテクノロジーが現在のレベルに到達すまでは、実現できませんでした。検証済みのマテリアルとプロシージャルジオメトリ生成を組合わせたリアルタイムのレイトレーシングにより、比較的小規模なチームが、さまざまな物理的に正確なシミュレーションを作成できるようになりました。合成シミュレーションは、アルゴリズムが失敗する可能性のある個所と理由の正確な境界線を見つけるために、世界中の自動車メーカーによって日常的に使われており、有用で必要と認められています。
自動運転の実用車に必要な多変量アプローチ
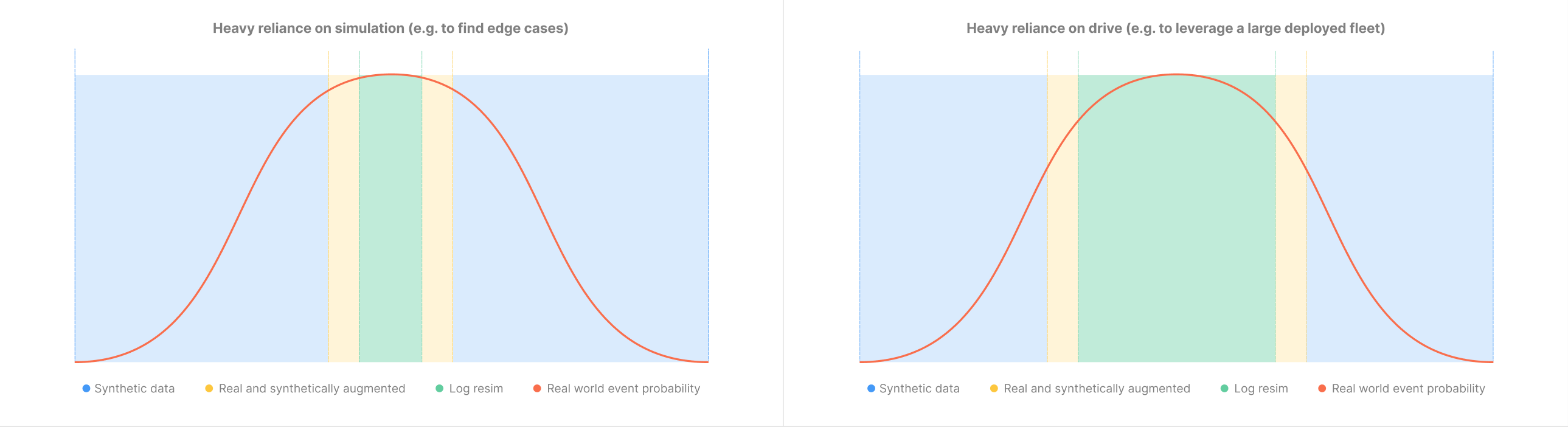
これらの方法を利用することにより、自律認識システムをテストするために潜在的に必要なシナリオとバリエーションの全領域をカバーすることができます。使用するAVシステムやアクセスできるドライブログに応じて、ツールの活用方法を変えれます。図3は、2つのシステムの例を示しています。左側のシステムは合成シミュレーションに大きく依存しており(エッジケースに焦点を当てるなど)、右側のシステムはドライブの再シミュレーションに重点を置いています(たとえば、運用された大規模なトラックフリートのデータを活用)。
結論
認識アルゴリズムとシミュレーションは、研究から実用へと移行しました。今回は開発の最先端で使用されているいくつかのアプローチについて説明し、これらの認識アルゴリズムで使用されるシミュレーションのコアとなる要件を示しました。この分野は絶えず進化しており、説明したシミュレーション方法とそのハイブリッドの新しい手法が編み出されるかもしれませんが、その技術を適用する大部分の課題は、実用車への応用にあります。
Applied Intuitionのアプローチ
今回説明したすべての認識シミュレーションアプローチをサポートするApplied Intuitionの製品群は、将来もこの分野での進化をサポートすることができます。弊社ではこれらのアプローチについて長年、研究開発を行ってきており、シミュレーションのご利用に興味がある方は、Applied Intuitionのエンジニアリングチームにぜひお問い合わせください。
